SPANN已经在bing上应用
SPANN has already been deployed into Microsoft Bing to support hundreds of billions scale vector search.
SPANN采用倒排索引的思路来处理巨量索引(Billon十亿级别)
总的思路有两个:
- Index structure:聚类中心放在内存中,posting list 放在disk中
- Partial search:对于query,只需要K个聚类中心,K « N(数据集总数据量)
遇到的挑战:
- Posting List 的长度限制:由于所有的Posting List中放在Disk中,为了减少Disk的访问,需要限制posting list的大小,使其可以通过少量的内存访问就能加载到内存中
- Boundary issue:聚类中心的边界点问题,一个cluster中,query和质心距离较远,但这个cluster中距离质心比较远的点,却有可能和query更近
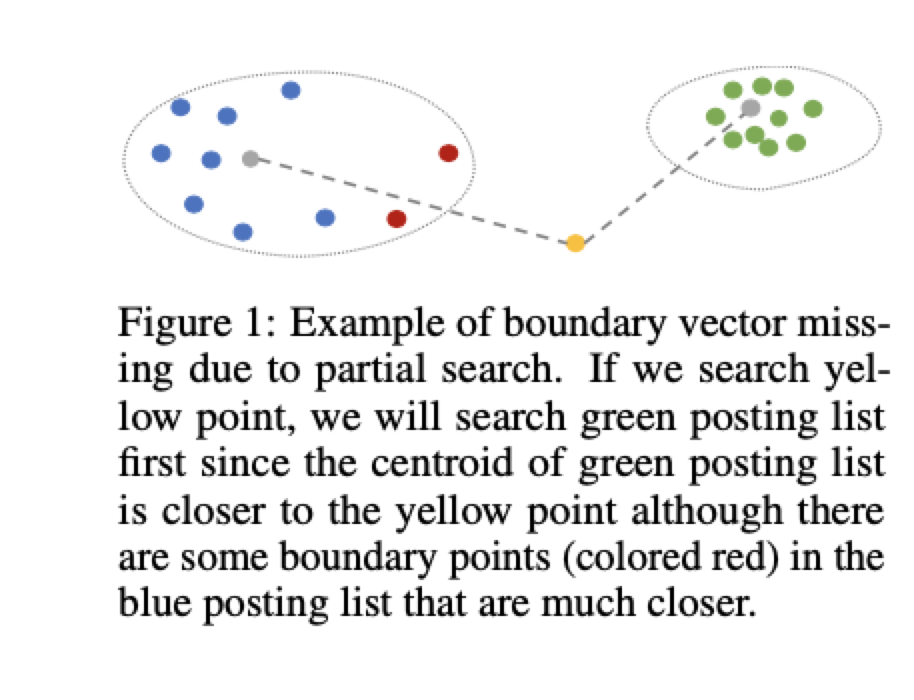
- Diverse search difficulty:不同的query需要扫描的cluster个数相差很大
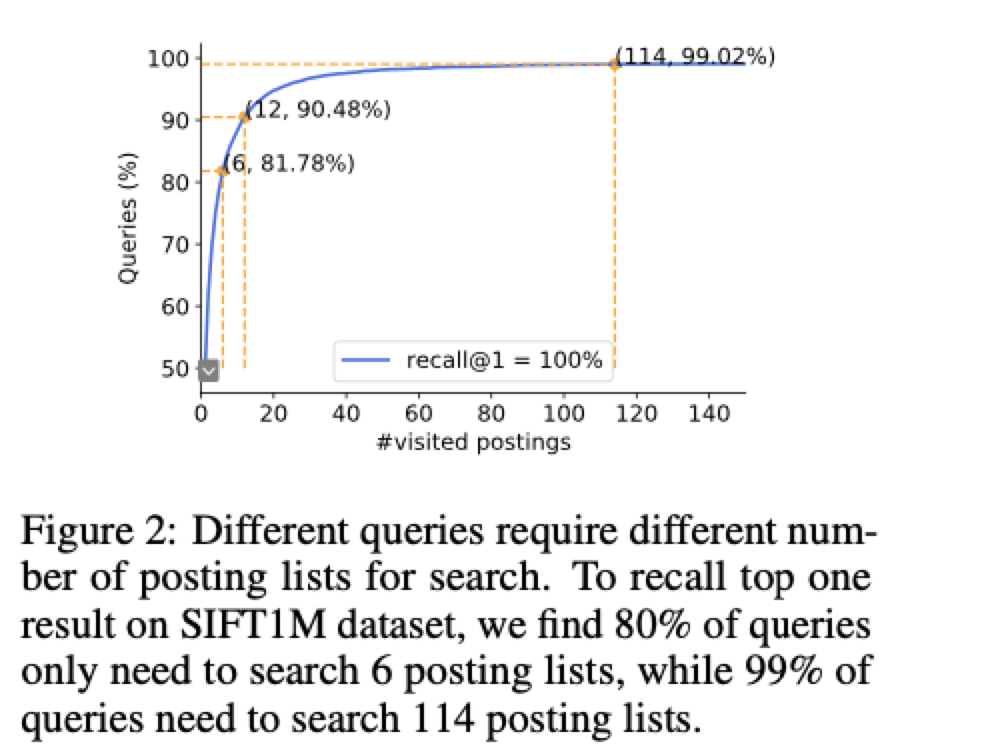
解决思路:
- Posting length limitation :通过改进的“多约束平衡机聚类算法”multi-constraint balanced clustering algorithm 生成均匀的posting lists,并优化了此原始聚类算法的时间复杂度。 另外,由于聚类中心(posting list)非常多,使用了一种ANN检索方法:SPTAG 来检索聚类中心。
- Posting list expansion :如果向量和多个聚类中心的距离相近,则想多个cluster中分配这个向量,而不仅仅是向最近的分配。
- 不同于简单的分配办法「将向量向最近的几个聚类中心分配(注意:这里没有“如果向量和多个聚类中心的距离相近”的前提)」,改进的分配办法以可以仅让“边缘向量”被复制。如果向量和某个聚类中心及其相近,其将不会被复制到多个cluster中,只会被分配到一个cluster中。
- 会有大量的点被复制,为了减少被复制的点的个数(减少磁盘IO),采用 RNG 规则来对被复制的点进行剪枝(只保留 Dist(cij,x) > Dist(cij−1,cij) 的复制),
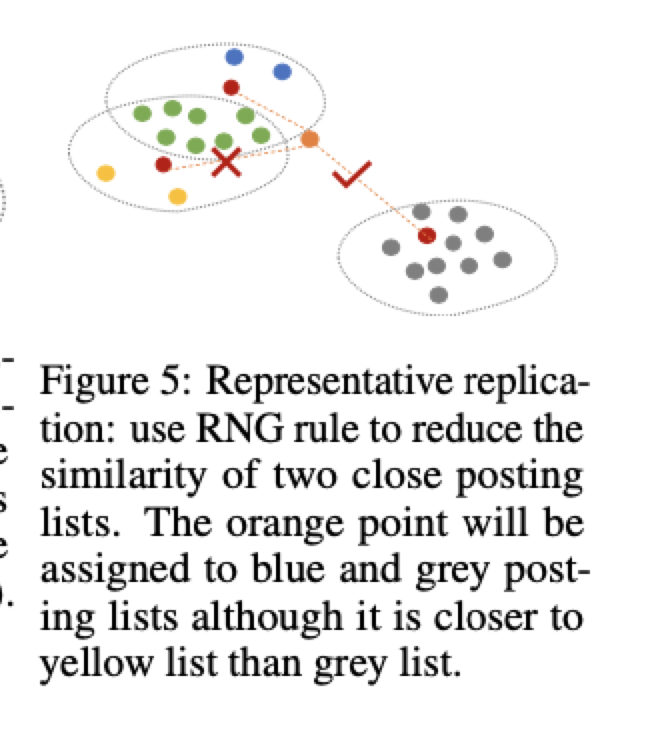
RNG算法示意图
- Query-aware dynamic pruning: 检索时动态剪枝。根据query与聚类中心们的距离来动态决定检索的posting list的个数。如果query与聚类中心的聚类相近的很多,那么选择更多的聚类中心。
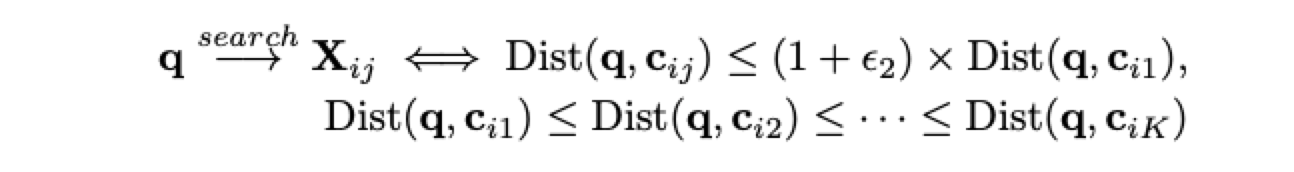
疑问:
- 论文没有写 IO 的测试,是否是比disk ANN有更多的IO次数?比DiskANN对Disk的IO速度有更高的要求?
- 论文没有写构建索引的速度,构建索引的速度如何?